⚓ About Me
My name is Haian Jin (金海岸), which means "Golden Coast" in Chinese.
I'm a Ph.D. student in Computer Science at Cornell University , advised by Prof. Noah Snavely .
My research lies at the intersection of computer Vision, graphics, and machine learning, with current interests in long-context learning, physical understanding, and world modeling. I am supported by the Google PhD Fellowship .
Previously, I completed my bachelor's degree (2019-2023) in Computer Science with honors from the Chu Kochen Honors College of Zhejiang University , ranking in the top 1%. During my undergraduate studies, I was fortunate to work closely with Prof. Hao Su (UCSD) and Prof. Xiaowei Zhou (ZJU).
📖 Publications
(* denotes equal contribution, and † denotes equal advisory.)
Selected Publications
All Publications
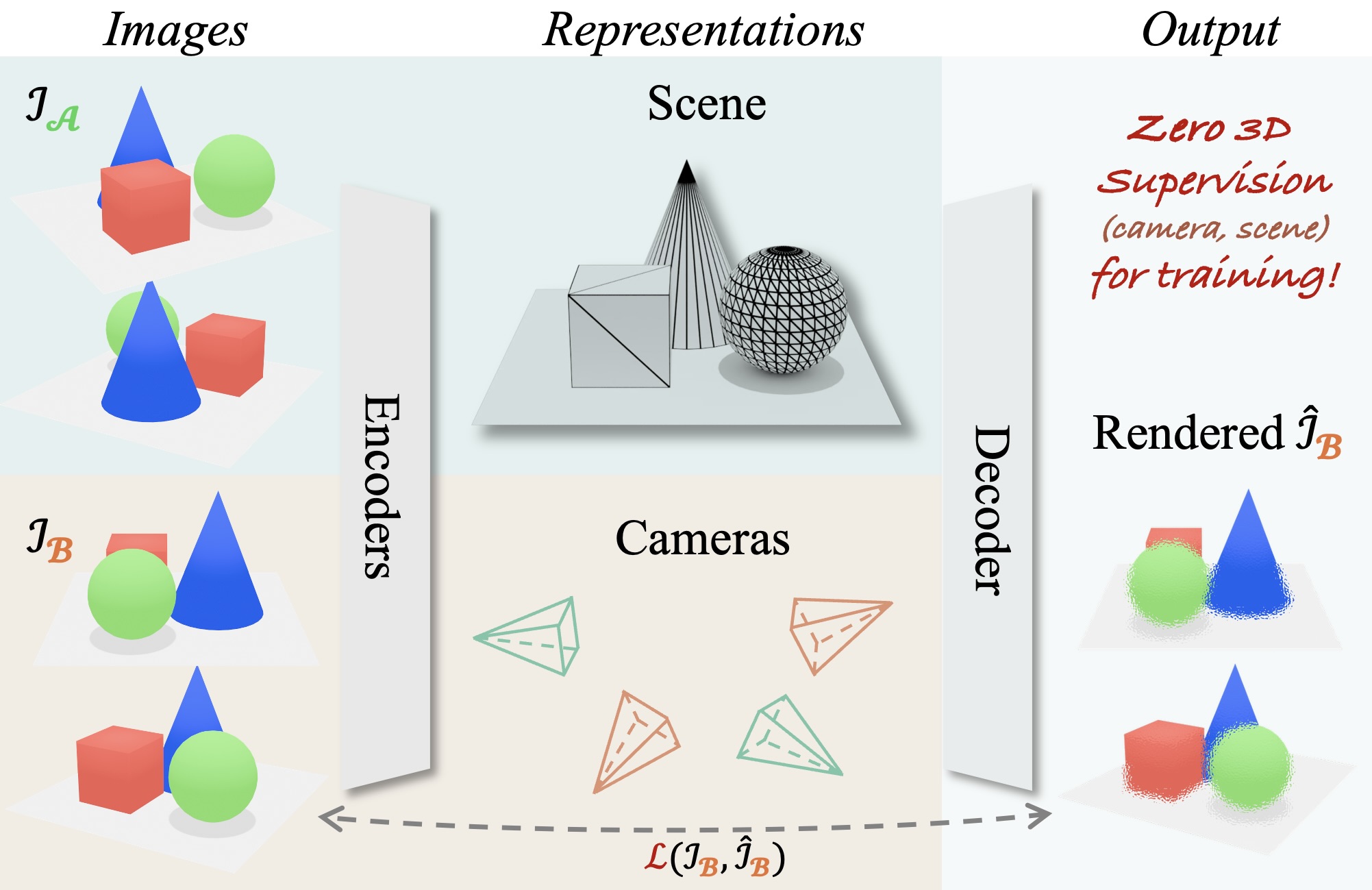
RayZer: A Self-supervised Large View Synthesis Model
Hanwen Jiang ,
Hao Tan ,
Peng Wang ,
Haian Jin ,
Yue Zhao ,
Sai Bi ,
Kai Zhang ,
Fujun Luan ,
Kalyan Sunkavalli ,
Qixing Huang ,
Georgios Pavlakos
ICCV 2025 (Oral Presentation, Best Student Paper Honorable Mention)
Your browser does not support the video tag.
MegaSynth: Scaling Up 3D Scene Reconstruction with Synthesized Data
Hanwen Jiang ,
Zexiang Xu ,
Desai Xie ,
Ziwen Chen ,
Haian Jin ,
Fujun Luan ,
Zhixin Shu ,
Kai Zhang ,
Sai Bi ,
Xin Sun ,
Jiuxiang Gu ,
Qixing Huang ,
Georgios Pavlakos ,
Hao Tan
CVPR 2025
Your browser does not support the video tag.
StreetCrafter: Street View Synthesis with Controllable Video Diffusion Models
Yunzhi Yan* ,
Zhen Xu* ,
Haotong Lin ,
Haian Jin ,
Haoyu Guo ,
Yida Wang ,
Kun Zhan,
Xianpeng Lang,
Hujun Bao ,
Xiaowei Zhou ,
Sida Peng
CVPR 2025
Your browser does not support the video tag.
LVSM: A Large View Synthesis Model with Minimal 3D Inductive Bias
ICLR 2025 (Oral Presentation)
Your browser does not support the video tag.
RelitLRM: Generative Relightable Radiance for Large Reconstruction Models
Tianyuan Zhang ,
Zhengfei Kuang ,
Haian Jin ,
Zexiang Xu ,
Sai Bi ,
Hao Tan ,
He Zhang ,
Yiwei Hu ,
Milos Hasan ,
William T. Freeman ,
Kai Zhang† ,
Fujun Luan†
ICLR 2025 (Spotlight)
Your browser does not support the video tag.
Neural Gaffer: Relighting Any Object via Diffusion
NeurIPS 2024
OpenIllumination: A Multi-Illumination Dataset for Inverse Rendering Evaluation on Real Objects
Isabella Liu* ,
Linghao Chen* ,
Ziyang Fu,
Liwen Wu ,
Haian Jin ,
Zhong Li,
Chin Ming Ryan Wong,
Yi Xu,
Ravi Ramamoorthi ,
Zexiang Xu ,
Hao Su
NeurIPS 2023 Datasets and Benchmarks
Your browser does not support the video tag.
One-2-3-45: Any Single Image to 3D Mesh in 45 Seconds without Per-Shape Optimization
NeurIPS 2023
Your browser does not support the video tag.
TensoIR: Tensorial Inverse Rendering
CVPR 2023